“Defcon zero. An entire Azure data center has been wiped out, billions of files have been lost.”
But not to worry, Azure will just fail over to another data center right? It’s automatic and totally invisible.
Well, not entirely. A failover doesn’t happen instantly so there’ll certainly be some downtime. There may also be more local connectivity concerns outside of Microsoft’s control that prevent connection. In these circumstances you might want to be able to access your replicated data until things are working properly again.
In Dec 2013 Microsoft previewed read-access geo redundant replication for storage accounts – which went Generally Available in May 2014. This means blobs, tables and queues are available for read access from a secondary endpoint at any time. Fortunately, third-party tooling and configuration scripts won’t need a complete re-write to support it, since the only thing you really need to do is use a different host for API requests.
Twice the bandwidth
Those who expect high performance from their Azure storage are may already be limiting reporting and other non-production operations. An additional benefit of the replicated data, is that you can divert all lower priority traffic to it, thus reducing the burden on the primary. Depending on the boldness of your assumptions, you could double the throughput to your storage by splitting unessential, ad hoc requests to the secondary endpoint.
Configuration
Replication can be configured in the Azure Management Portal to one of three modes: off, on, and on with read access. Officially these three modes are called:
- Locally redundant. Data is replicated three times within the same data center.
- Geo redundant. Replication is made to an entirely separate data center, many miles away.
- Read access geo redundant. Replication is geo redundant and an additional second API endpoint is available for use at any time, not just after an emergency failover.
What can’t be configured is the choice of secondary location. Each data center is ‘paired’ with another – for example, North Europe is paired with West Europe, and West US is paired with East US. This also keeps the data within the same geo-politcal boundary (the exception being the new region in Brazil, which does its secondary in South Central US).
Behavioural matters
In a simple usage scenario, it’s unlikely you’ll run into issues with consistency between your primary and secondary storage. For small files you might only see a latency of few seconds. Whilst MS have not issued an SLA guarantee at this time, they state that replication should not be more than 15 minutes behind. For reporting purposes, you might not care about such a low latency. In any case, you can query the secondary endpoint to find out when the last synchronisation checkpoint was made.
It’s worth pointing out that transactions may not be replicated in the order that they were made. The only operations guaranteed to be made in order are ones relating to specific blobs, table partition keys, or individual queues. Replication does respect the atomicity of batch operations on Azure Tables though, and will be replicated consistently.
Accessing the endpoint
Accessing the replicated data is done with the same credentials and API conventions, except that ‘-secondary’ is appended to the subdomain for your account.
For example, if the storage account ordinarily has an endpoint for blob access such as https://robinanderson.blob.core.windows.net then the replicated endpoint will be https://robinanderson-secondary.blob.core.windows.net. Note that this DNS entry won’t even be registered unless read access geo redundant replication is enabled. This does mean that if someone knows your storage account name, they can tell if you have this mode enabled by trying to ping your secondary endpoint, for all the good it will do them.
When connecting to the secondary endpoint authentication is performed using the same keys as for the primary. Any delegated access (for example, SAS) will also work since these are validated using these keys.
Analytics
If monitoring metrics are enabled for blob, table or queue access, then those metrics will also be enabled for the secondary endpoint. This means there are twice as many metrics visible on the secondary, as the primary ones are replicated over as well.
Simply replace the word ‘Primary’ with ‘Secondary’ in the table name to access the equivalent metric, thus $MetricsHourlyPrimaryBlobTransactions becomes $MetricsHourlySecondaryBlobTransactions.
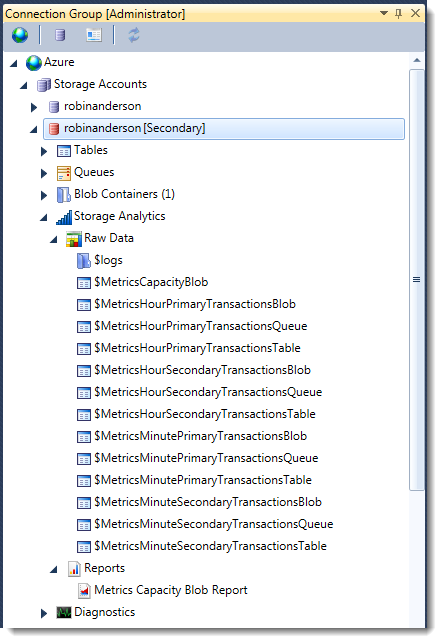
At the time of writing, there is no equivalent for the $logs blob container. Ordinarily, you can audit all read, write and delete operations made to your storage account. So whilst the aggregate monitoring analytics mentioned above are available for the secondary endpoint, you won’t know specifically which source IP addresses are issuing reads (though it’s unlikely you’d care).
Support for secondary storage in Azure Management Studio
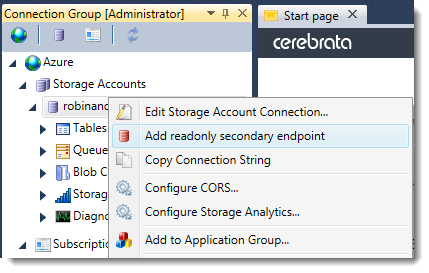
Accessing the replicated data in AMS is fairly trivial if you’ve already got the original storage account registered – just right click and choose ‘Connect to geo-redundant secondary copy’ from the storage account context menu and a second, rather similar, storage account will be visible next to the first. It will behave entirely as if it were an ordinary storage account, except that it will be read-only and will display the last synchronisation time in the status bar.
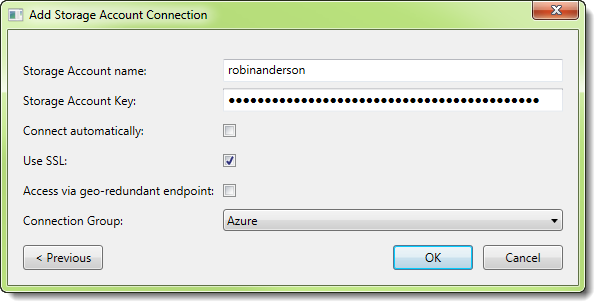
Alternatively, there’s a checkbox on the ‘Add storage account’ dialog that allows you to specify access via the secondary endpoint, if you’ve not already registered the primary. Either way, once you’re looking at your data you can use the same UI features to search, query and download.
To try out this new feature download your free trial of Azure Management Studio now. Existing users can get the latest version from within Azure Management Studio (go to Help – Check for Updates).